8 Training and Testing
When building models, it is important to evaluate how well they perform on new, unseen data. If we only evaluate a model on the same data it was trained on, we can get overly optimistic results.
8.1 Why Split the Data?
If we train and test on the same dataset:
- the model has already “seen” the data
- it can appear more accurate than it really is
- we cannot tell how well it will perform in practice
To address this, we split the data into:
-
Training set → used to fit the model
- Test set → used to evaluate performance
8.2 Create Train and Test Sets
- 80% of the data is used for training
- 20% is held out for testing
8.3 Train the Model
lm_train <- lm(body_mass_g ~ bill_length_mm + bill_depth_mm + flipper_length_mm, data = train)The model is fit only on the training data.
8.4 The Wrong Way: Evaluate on Training Data
[1] 397.3888- This often produces a low error
- But it is misleading because the model has already seen this data
This is like studying using the exact answers to the test.
8.5 The Correct Way: Evaluate on Test Data
[1] 364.3985- This gives a more realistic estimate of performance
- It reflects how the model behaves on new data
8.6 Visualizing Predictions
eval_df <- test
eval_df$predicted_body_mass_g <- test_preds
ggplot(eval_df, aes(x = body_mass_g, y = predicted_body_mass_g)) +
geom_point() +
geom_abline(slope = 1, intercept = 0, linetype = "dashed") +
labs(title = "Test Set Predictions")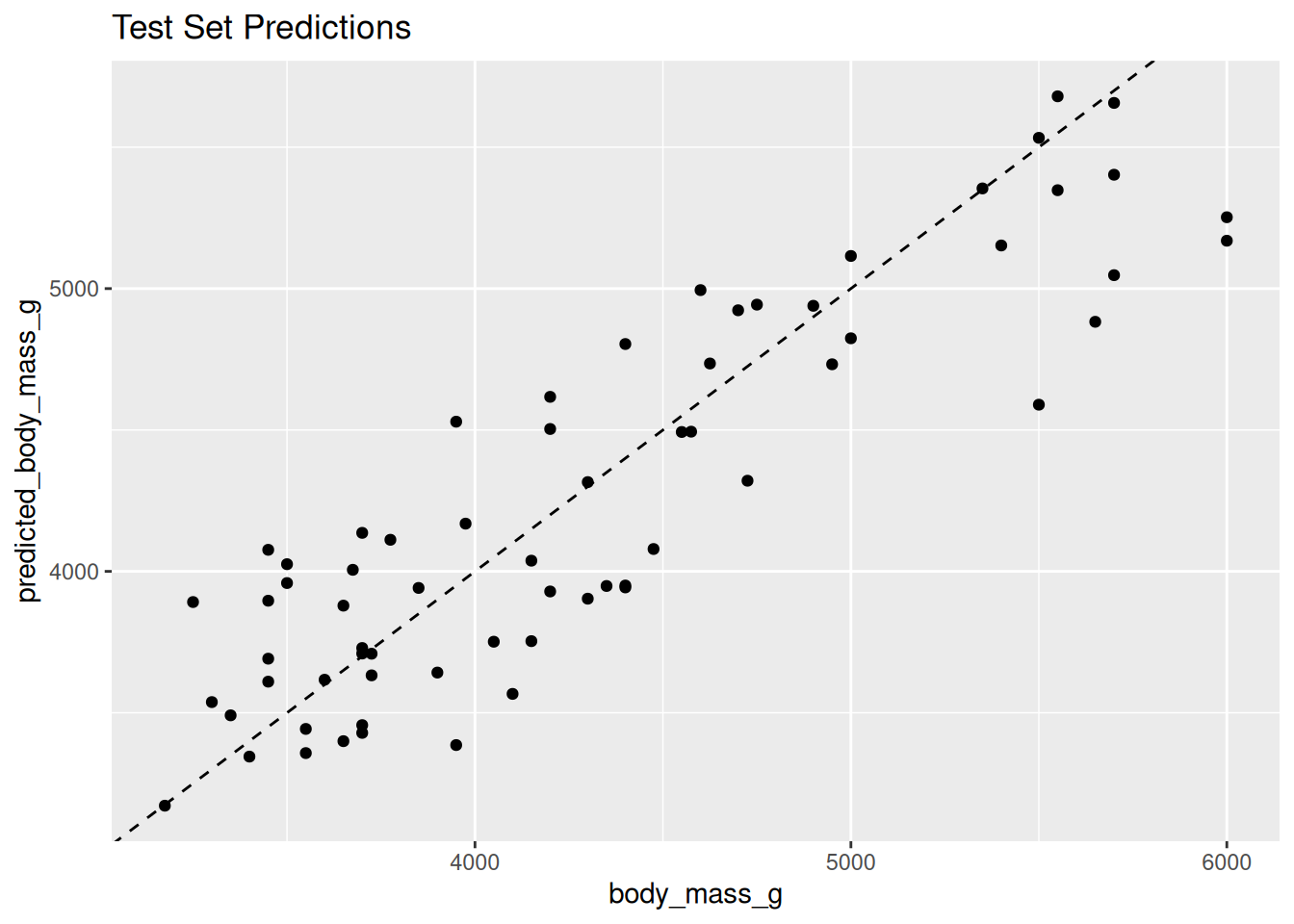
- Points close to the dashed line indicate good predictions
- Larger deviations indicate prediction errors
8.7 Key Takeaways
- Always evaluate models on data they have not seen
- Training error is often misleading
- Test error provides a better estimate of real-world performance
A good model is not one that fits the training data perfectly,
but one that generalizes well to new data.