Text data mining (TDM)#
What is Data?
What is Text data mining (TDM)?
What is Text as Data?
What are Types of Text Mining?
What is Data ?#
We begin without data. Then it is observed, or made, or imagined, or generated. After that, it goes through further transformations.
“What are the differences between data, a dataset, and a database?
Data are observations or measurements (unprocessed or processed) represented as text, numbers, or multimedia.
A dataset is a structured collection of data generally associated with a unique body of work.
A database is an organized collection of data stored as multiple datasets. Those datasets are generally stored and accessed electronically from a computer system that allows the data to be easily accessed, manipulated, and updated. - Definition via USGS
For the purposes of this workshop, we recommend finding an already existing data set for your project, as creating, cleaning and/or structuring a new dataset is often time and labor intensive.
Remember that just because data may be avaible digitally, it does not automatically exist as a dataset. You may have to do works manually (copying and pasting into a spreadsheet) or computationally (scarping the data) to create a dataset usable for computational analysis.
Read more about Data Prep and Cleaning and Cleaning Text Data
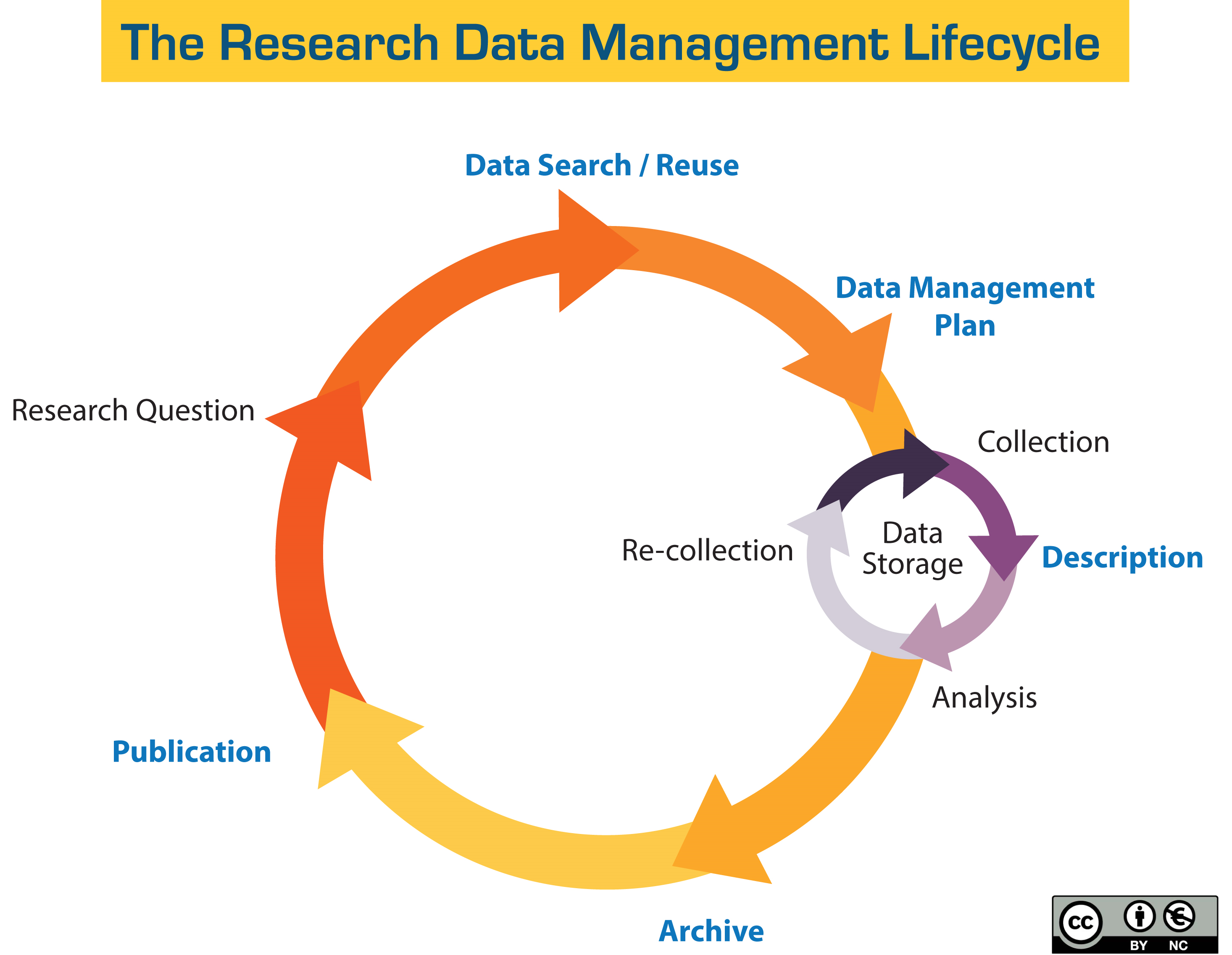
Forms of data#
There are many ways to represent data, just as there are many sources of data. For the purposes of this series we are focusing on already digitized text.
Raw data#
Raw data is yet to be processed, meaning it has yet to be manipulated by a human or computer. Received or collected data could be in any number of formats, locations, etc.. It could be in any number of forms.
But “raw data” is a relative term, inasmuch as when one person finishes processing data and presents it as a finished product, another person may take that product and work on it further, and for them that data is “raw data”.
For example, is “big data” “raw data”? How do we understand data that we have “scraped”?
Processed/transformed#
Processing data puts it into a state more readily available for analysis, and makes the data legible. For instance it could be rendered as structured data. This can also take many forms, e.g., a table. We will discuss what this means for text data (OCR, Tokenizing, etc.).
Data mining#
Data mining is looking for patterns using computational methods, often across large data sets.
Computer algorithms can discern patterns in bodies of (often unstructured) text.
“Unstructured” means that little is known about the semantic meaning of the text data and that it does not fit a defined data model or database.
An algorithm is simply a computational process that creates an output from an input. * In text analysis, the input would be the unstructured text, and the output would be indicators to help you reveal different things about the text.
What is TDM?#
“The difference between regular data mining and text mining is that in text mining the patterns are extracted from natural language text rather than from structured databases of facts.”
Text analysis can be used for a variety of purposes. It can be used for exploratory and analytical research, such as seeking out patterns in scientific literature to pick up trends in medical research otherwise difficult to see from the vantage point of an individual reader. It can also be used in developing tools that we use in our daily lives, for example creating spam filters to identify spam e-mail.
TDM projects#
For a TDM project you need to complete the following steps:
Identify a research question or topic of interest.
Data gathering or Data Search
Search for and identify a data set that is available for use and relevant to your research interests.
For an introductory project, we recommend you find and use an already existing data set, rather then creating and/or cleaning a new dataset.
Data preparation
The text needs to be transformed from a form that human readers are familiar with to something that the computer can “read”.
The text is broken into smaller pieces and abstracted (reduced) into things that a computer can process.
Text analysis
Counting is often what happens next.
Some of the things that are often counted include words, phrases, and parts of speech (POS).
The number of these counts can be used to identify characteristics of texts.
Then, researchers can apply computational statistics to the counts of textual features, and develop hypotheses based on these counts.
Do you have a specific question you are trying to answer or are you doing an exploratory project?
What type of analysis are you interested in? It may be useful to look for an article in your field on a topic you are interested in to see what the process will be like. The data and methodology sections are always useful to read to see where people are finding data and how they are analyzing it.
Visualization
How will you communicate your findings?
How does it impact research?#
In a general sense, the shift in the researcher’s perspective leads to shifts in research questions. Text analysis techniques are sometimes called “distant reading.”
This is a term attributed to Franco Moretti, meaning “reading” literature not by studying particular texts, but by aggregating and analyzing massive amounts of texts and “reading” them at a “distance”. This scaling-up and “distancing” can bring out more insights from a very different vantage point.
It is also worth mentioning that text analysis doesn’t have to be the primary method in a research project. It may be just one step in the entire process, or it can be combined with close reading. This approach has been called “intermediate reading” or “distant-close reading”.
This shift in research perspective allows for new kinds of research questions to be asked, or for old questions to be “answered” in new ways. Here are some of the possibilities that text analysis can bring to researchers:
It can explore questions not provable by human reading alone
It allows larger corpora for analysis
It allows studies that cover longer time spans
Text analysis techniques are often best when combined with qualitative assessment and theoretical context.
Text analysis research questions explore a wide range of topics, from biomedical discovery to literary history. Research questions that are conducive for text analysis methods may involve these characteristics:
Change over time
Pattern recognition
Comparative analysis
Text analysis research examples from HTRC
How do the projects involve change over time, pattern recognition, or comparative analysis?
What kind of text data do they use (time period, source, etc.)?
What are their findings?
What kind of texts do I need for text analysis?#
Text analysis depends on having a large number of texts in an accessible format. Since many text analysis methods rely on statistical models, it is generally true that having more texts (a text corpus) will improve the outcomes of your analysis.
It is also generally true that an ideal set of texts—or corpus—will be:
Full-text
Easily readable, such as plaintext files or Python strings
In practice, “easily-readable” means that you could hypothetically copy and paste the text. This may be made complicated if working with works which are in copyright. If it is not possible to access “full-text” due to applicable copyright laws, the ideal corpus will give readers access to metadata or n-gram counts. (N-grams are a contiguous chain of n-items (i.e. words) where n is the number of items in the chain.)
While having the full texts for the documents in your corpus is ideal, a great deal can be still be discovered through the use of unigrams. Even when researchers have access to the full-texts of a corpus, it is common for them to create a list of n-gram counts for analysis.
What is Text as Data ?#
When approaching text as data, here are some things to keep in mind:
First, having textual data of sufficient quality is important. Textual data quality is determined by how it’s created. Hand-keyed text is often of the best quality, while text obtained by OCR, Optical Character Recognition, can vary in quality. Raw, uncorrected OCR text is dirty, and it can only become clean until it is corrected. (For example, Please note that HathiTrust OCR is dirty and uncorrected.
When viewing text as data, we usually analyze them by corpus or corpora. As mentioned in previous modules, a “corpus” of text can refer to both a digital collection and an individual’s research text dataset. Text corpora are bodies of text.
When preparing text, one can think in terms of what Geoffrey Rockwell has called text decomposition or re-composition. The text will be split, combined, or represented in ways that distinguish it from human readable text. It may involve discarding some text, and requires the researcher to shift their understanding of the text from human-legible object to data. What stays, what goes, and how things are manipulated is a researcher’s choice. While there are emerging best practices, there isn’t a step-by-step guide to follow.
I have my own data. What will it take to get it ready?#
Finding, cleaning and structuring data is often time consuming and labor intensive. One of the most significant benefits of using a database such as HathiTrust Digital Library, Constellate by ITHAKA or any database with a dataset builder is that it takes out the vast majority of effort in doing text analysis.
For a major text analysis project, such as UNC Chapel Hill’s On the Books: Jim Crow and Algorithms of Resistance, about 90% of the labor is creating the corpus. For your initial project we suggest assembling a data set from one of the previously mentioned databases.
If you have your own data, you will need to assess what it will take to make it ready for analysis. Here are some questions you should ask:
Do I need to use Optical Character Recognition (OCR) to convert my data into plain text?
Do i need to tokenize (break up and separate the words) my texts?
Consider the data’s current form as well as your current skill level or the size and skill of your project staff. The corpus creation process could take anywhere from a few hours to many years of labor.
If there is a significant amount of labor, you may need to write a grant proposal to hire help.
If writing a grant, contact your library with questions about Research Data Management since funding agencies often require your corpus to be committed to a disciplinary or institutional repository.
In addition to the cleaned-up texts for your corpus, you will also need a strategy for dealing with textual metadata, information such as author, year, etc. It helps to have some experience with working with data at scale with either Excel or Python Pandas.
Read about analyzing U.S. political party platforms on women’s issues
Read about examining chyrons (the text at the bottom of the screen) from three major cable networks
Read about The Emergence of Literary Diction
Searching for Text Data#
You can search for already existing datasets in the following:
Databases
Licensed content in Library databases
Only some databases allow for text mining without additional permissions. Those are marked on our A-Z list with the filter Text Mining
-
Additional resources for Datasets and Data Repositories
Policies for Mining Licensed Content
If you are thinking of basing a research project on data extracted from a library database, contact your subject librarian to discuss issues around permissions (copyright and licensing agreements), formats and fees.
In addition to copyright considerations, we must take into account what the database vendors’ own policies specify in regard to this type of use. When providing access to a database, the library enters into licensing agreements, which also dictate what types of data can be extracted and used. Many prohibit text and data mining and the use of software such as scripts, agents, or robots, but it may be possible to negotiate text mining rights.
Non-consumptive or non-expressive use
Research in which computational analysis is performed on text, but not research in which a researcher reads or displays substantial portions of the text to understand the expressive content presented within it.
Non-consumptive research complies with copyright law because of the distinction in law between “ideas” and “expressions”. It is sometimes called non-expressive use (because it works with “ideas” instead of specific “expressions”, hence the term “non-expressive”).
Non-consumptive research complies with copyright law because of the distinction in law between “ideas” and “expressions”. It is sometimes called non-expressive use (because it works with “ideas” instead of specific “expressions”, hence the term “non-expressive”).
Foundation of HTRC work.
Open access (OA) or Public Domain information
You can search the open web using a web browser such as Chrome or Firefox, adding specific terms such as: data, datasets, API, file format (such as .csv). Advanced search options amy also allow for searching for specific file types. Try searching:
You can also look at the archive for Data Is Plural a weekly newsletter of datasets
Depending on the the type of data, the collecting agency or you field their might be open access repositories with that data available.
Data collected by the U.S. government may be publicly available.
Your discipline may have a OA repository, such as arXiv, which has articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
Highly recommended practice#
Read the Data and methodology sections of research and/or data journalism articles! When you are considering learning new methodologies, we highly recommend searching for academic or data journalism articles where the authors have asked similar questions or used related methodologies.
When reading these articles, pay particular attentions to the literature review, and to the data and methodology sections.
Where did these researchers find their data set they are using?
If they created it, did they make it accessible in a repository on a website, or a Github repository?
Read some data journalism articles on The Pudding, ProPublica or this roundup of data journalism projects from 2021
Preparing Data (Cleaning and Transforming)#
After gathering the data needed for research and before conducting the actual analysis, data often requires preparation (also sometimes refereed to as pre-processing the data). Preparing data can take a lot of time and effort.
Preprocessing specifically for text will include
Cleaning text data can involve…
Removing Duplicates
Correcting Errors
Removing Outliers
Adjusting for Missing data
Correcting OCR errors.
Removing title and header information
Removing html or xml tags.
Splitting or combining files.
Removing certain words or punctuation marks.
Making text into lowercase.
The importance of using open data formats#
A small detour to discuss data formats. For accessibility, future-proofing, and preservation, keep your data in open, sustainable formats.
Sustainable formats are generally unencrypted, uncompressed, and follow an open standard. A small list:
ASCII
PDF
.csv
FLAC
TIFF
JPEG2000
MPEG-4
XML
RDF
.txt
.r
How do you decide the formats to store your data when you transition from ‘raw’ to ‘processed/transformed’ data? What are some of your considerations?
Tidy data (structured data)#
There are guidelines to the processing of data, sometimes referred to as Tidy Data.1 One manifestation of these rules:
Each variable is in a column.
Each observation is a row.
Each value is a cell.
{"Cats":[
{"Calico":[
{ "firstName":"Smally", "lastName":"McTiny" },
{ "firstName":"Kitty", "lastName":"Kitty" }],
"Tortoiseshell":[
{ "firstName":"Foots", "lastName":"Smith" },
{ "firstName":"Tiger", "lastName":"Jaws" }]}]}
1Wickham, Hadley. “Tidy Data”. Journal of Statistical Software.
Chunking text#
As mentioned, preparing text often involves splitting and combining files. In text analysis, splitting files is commonly referred to as chunking text. It means splitting text into smaller pieces before analysis. The text may be divided by paragraph, chapter, or a chosen number of words (e.g. 1000 word chunks). Let’s say that we have a whole text that consist of speeches of Abraham Lincoln. Before conducting analysis, the researcher may need to split the text into individual speeches. This process can be called chunking text.
Grouping text#
An opposite process that needs to be done just as often is combining text into larger pieces before analysis, which can be referred to as grouping text. Let’s look at political speeches as an example. Say that this time we have individual texts of various speeches made by Abraham Lincoln as well as George Washington. Before conducting our analysis, we may need to group the texts by combining all speeches by Lincoln into one group and all speeches by Washington into another group.
Both chunking and grouping are ways of modifying the unit of analysis for the researcher, and it’s wholly dependent on what the researcher wants to study. Maybe someone wants to compare all of Abraham Lincoln’s speeches to all of George Washington’s speeched. They could create two large “buckets” of data via chunking. Or someone only wants to compare the chapters in John F. Kennedy’s “Profiles in Courage” to see how descriptions of the figures it profiled are similar or different, then a researcher might split a single work out by chapter. Those are simplistic examples, but they highlight the kinds of splitting and combining that may happen.
Tokenization#

An additional step in preparation is called tokenization. Tokenization is simply the process of breaking text into pieces called tokens. Often certain characters, such as punctuation marks, are discarded in the process. Here’s a tokenized version of the beginning of The Gettysburg Address on the image above. The original text, which is in a human-readable form, has been translated into tokens. While the tokens can still be parsed by a human, it isn’t in a form we regularly read. It can now, however, be read and processed by a computer.
It is important to note that different choices in text preparation will affect the results of the analysis.
Depending on the amount of text and size of chunks, which stop words are removed and which characters are included, and whether to lowercase and normalize words, the eventual text that is ready for analysis can be very different. Additionally, preparation for analysis takes a lot of time and effort. This is where scripting becomes useful!
Additional information about how text preparation impacts results
Types of Text Mining#
What disciplinary questions can text analysis answer?#
You can use text analysis to answer a wide variety of questions.
Here are a few that are common:
What are these texts about?
How are these texts connected?
What emotions (or affects) are found within these texts?
What names are used in these texts?
Which of these texts are most similar?
1. What are these texts about?#
When it comes to a large body of texts, scholars tend to be most curious about the text’s contents. What are the words, topics, concepts, and significant terms in these documents? There are a number of methods often used which vary in complexity and difficulty.
Word Frequency#
Counting the frequency of a word in any given text. relative frequency – how often do words appear relative to other words in the text, typically a percentage Common as a baseline for more sophisticated methods This includes Bag of Words and TF-IDF. Example: “Which of these texts focus on women?”
If you search for digital humanities in Google image search, the most common result is a word cloud. A word cloud visualizes the most frequent content words in a text or corpus.
Before you can create a word cloud, however, you need to collect the word frequencies for all the words in your text. You may also need to use a stop words list to remove common function words (grammatical word constructions like “the”, “of”, and “or”).
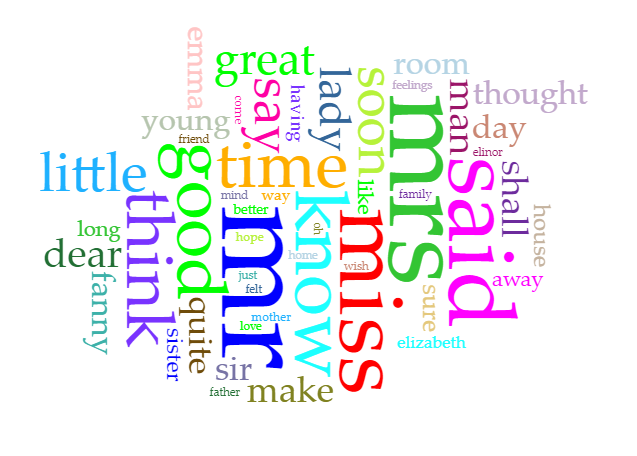
Image source:Voyant Cirrus image, Austen corpus
Collocation#
Examining where words occur close to one another. Example: “Where are women mentioned in relation to home ownership?”
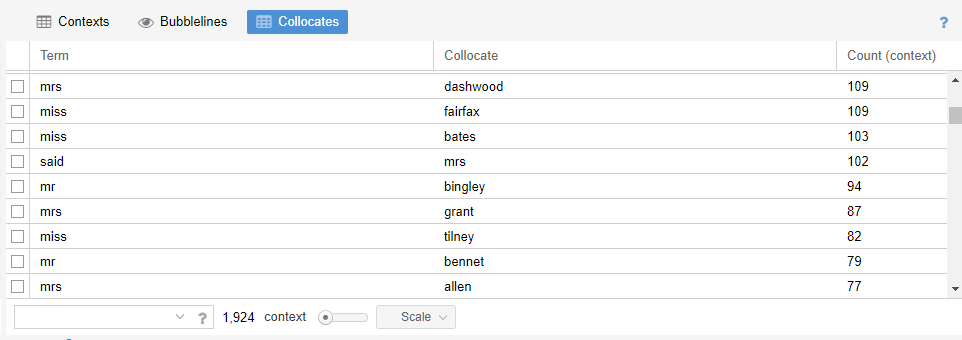
Image source:Voyant Collocation image, Austen corpus
A type of collocation is n-gram counts.
N-grams are a contiguous chain of n-items (i.e. words) where n is the number of items in the chain.

In the cases where a database (such as Constellate or Hathitrust) cannot supply full-text due to copyright laws, they may supply three n-gram counts:
Unigrams - A single-word construction, for example: “vegetable”.
Bigrams - An two-word construction, for example: “vegetable stock”.
Notice how in the bigram example above the window of the gram slides across the text, so in bigrams, a word will occur with both the word preceding and following it.
Trigrams- A three-word construction, for example: “homemade vegetable stock”.
While having the full texts for the documents in your corpus is ideal, a great deal can be still be discovered through the use of unigrams. Even when researchers have access to the full-texts of a corpus, it is common for them to create a list of n-gram counts for analysis.
Read about using n-grams to get a sense of language usage and change on Reddit
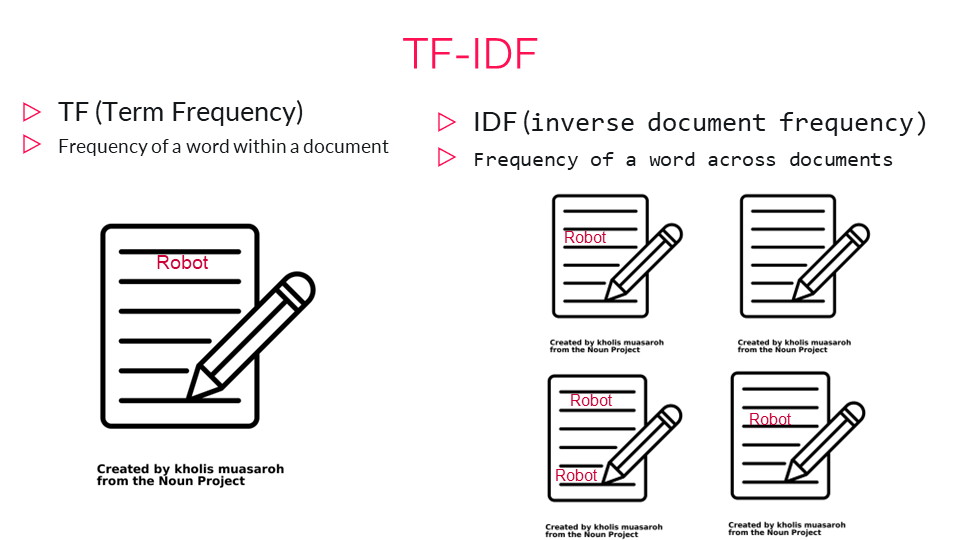
TF/IDF#
Tf-IDF (term frequency–inverse document frequency) is intended to reflect how important a word is to a document in a collection or corpus. Example: “Given a decade of board reports, are there seasonal issues that crop up in summer vs. winter?”
Significant Terms#
Search engines use significant terms analysis to match a user query with a list of appropriate documents. This method could be useful if you want to search your corpus for the most significant texts based on a word (or set of words). It can also be useful in reverse. For a given document, you could create a list of the ten most significant terms. This can be useful for summarizing the content of a document.
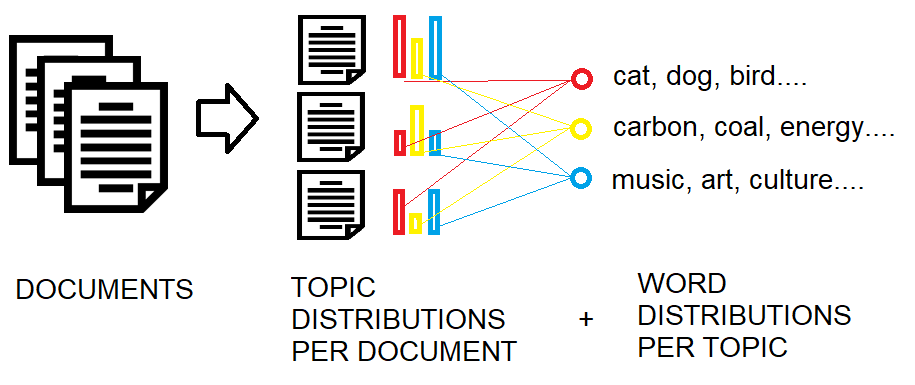
Topic Modeling#
Topic modeling is a method of using statistical models for discovering the abstract “topics” that occur in a collection of documents.
{kind=link}
For this kind of analysis, the text is chunked, and stop words (frequently used words such as “the”, “and”, “if”) are removed since they reveal little about the substance of a text. * Discovering the topics within a group of texts. Example: “What are the most frequent topics discussed in this newspaper?”
While significant terms analysis reveals terms commonly found in a given document, a topic analysis can tell us what words tend to cluster together across a corpus. For example, if we were to study newspapers, we would expect that certain words would cluster together into topics that match the sections of the newspaper. We might see something like:
Topic 1: baseball, ball, player, trade, score, win, defeat
Topic 2: market, dow, bull, trade, run, fund, stock
Topic 3: campaign, democratic, polls, red, vote, defeat, state
We can recognize that these words tend to cluster together within newspaper sections such as “Sports”, “Finance”, and “Politics”. If we have never read a set of documents, we might use a topic analysis to get a sense of what topics are in a given corpus. Given that Topic Analysis is an exploratory technique, it may require some expertise to fine-tune and get good results for a given corpus. However, if the topics can be discovered then they could potentially be used to train a model using Machine Learning to discover the topics in a given document automatically.
Programming Historian: What is Topic Modeling And For Whom is this Useful?
Walkthrough: Topic Modeling Using Latent Dirichlet Allocation (LDA)
Bag of words#
The computer treats the textual documents as bags of words, and guesses which words make up a “topic” based on their proximity to one another in the documents, with the idea the words that frequently co-occur are likely about the same thing. So the different colored groupings are the groups of words that the computer has statistically analyzed and determined are likely related to each other about a “topic”.
“Bag-of-words” is a concept where grammar and word order of the original text are disregarded and frequency is maintained. Here is an example of the beginning of The Gettysburg Address as a bag of words.

Here are some tips for topic modeling:
Treat topic modeling as one part of a larger analysis.
Understand what you input, including how you set your parameters, will affect the output. Some points to note are:
Be careful with how you set the number of texts analyzed, as well as number of topics generated
Be familiar with your input data
Know that changing your stop word list can have really interesting impacts on your topics, so tread carefully/wisely.
You’re going to want to go back to the text at some point. Make sure to examine your results to see if they make sense.
Read more Keli Du’s A Survey on LDA Topic Modeling in Digital Humanities
2. How are these texts connected?#
Concordance#
Where is this word or phrase used in these documents? Example: “Which journal articles mention Maya Angelou’s phrase, ‘If you’re for the right thing, then you do it without thinking.’”
The concordance has a long history in humanities study and Roberto Busa’s concordance Index Thomisticus—started in 1946—is arguably the first digital humanities project. Before computers were common, they were printed in large volumes such as John Bartlett’s 1982 reference book A Complete Concordance to Shakespeare—it was 1909 pages pages long! A concordance gives the context of a given word or phrase in a body of texts. For example, a literary scholar might ask: how often and in what context does Shakespeare use the phrase “honest Iago” in Othello? A historian might examine a particular politician’s speeches, looking for examples of a particular “dog whistle”. See in the image below, all instances of “cousin” in a Shakespeare concordance.

Image source: Concordance of Shakespeare’s complete works
Network Analysis#
How are the authors of these texts connected? Example: “What local communities formed around civil rights in 1963?”
in the image below, The circles (nodes) in the graph represent individual newspapers or magazines, while the lines between them (edges) represent shared texts.
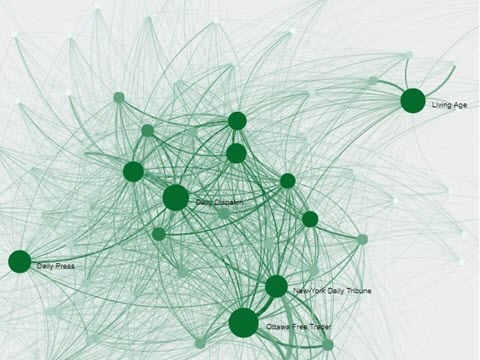
3. What emotions (or affects) are found within these texts?#
Sentiment Analysis#
Sentiment analysis, which uses computers to explore what emotions are present in the text. Does the author use positive or negative language? Example: “How do presidents describe gun control?” Sentiment analysis can help determine the emotions expressed in a given text. This can be determined using rule-based algorithms, Machine Learning, or both.
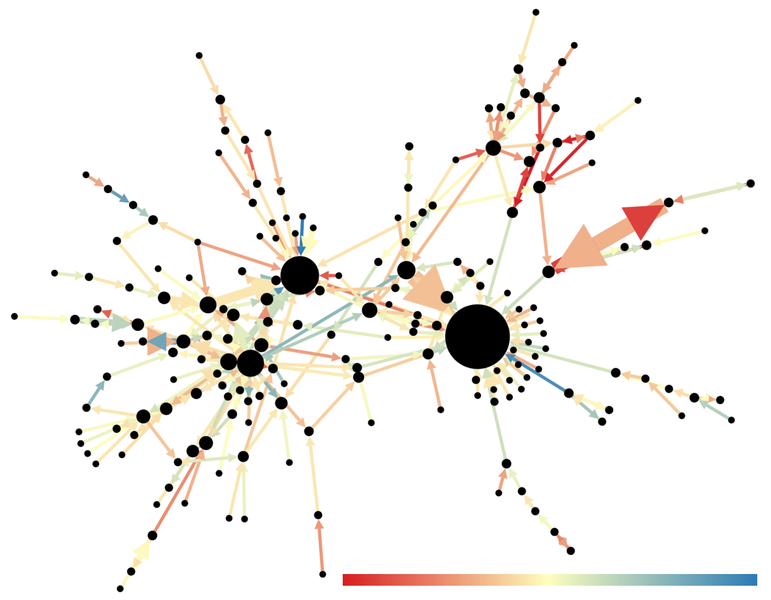
{kind=link}
Read about:
4. What names are used in these texts?#
Named Entity Recognition** (or NER)#
Named Entity Recognition (NER) automatically identifies entities within a text and can helpful for extracting certain kinds of entities such as proper nouns. For example, NER could identify names of organizations, people, and places. It might also help identify things like dates, times, or dollar amounts.
You can use NER to list every example of a kind of entity from these texts. Example: “What are all of the geographic locations mentioned by Tolstoy?”

Image source: SpaCy Named Entity
Read more
Miguel Won, Patricia Murrieta-Flores, and Bruno Martins Ensemble Named Entity Recognition (NER): Evaluating NER Tools in the Identification of Place Names in Historical Corpora (2018)
Read about about how hyphenated names are hard to study here
5. Which of these texts are most similar?#
Machine Learning(ML)#
Another key approach to text analysis is *Machine Learning (ML). ML is training computers to recognize patterns in text.
Machine learning can either be unsupervised (with minimal human intervention) or supervised (with more human intervention).
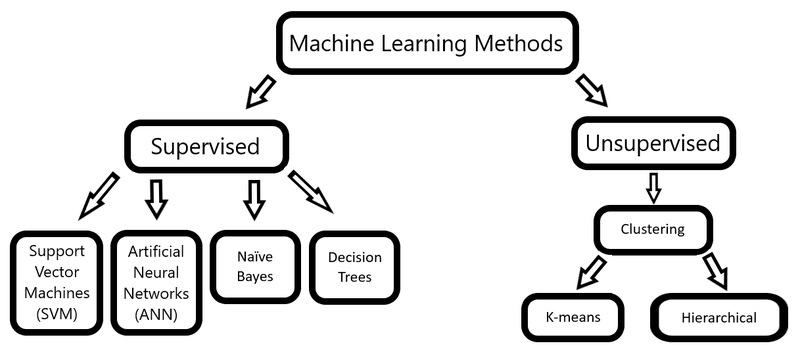
Image source: hellisp, Wikimedia
{kind=link}
Here are some common, specific methods that are based on machine learning:
Topic modeling, which explores the thematic topics present in the text. Remember that topic modeling is a bag-of-words approach.
Naïve Bayes classification, which explores the categorization of texts, i.e. determining what categories that the researcher have named does a certain text belong to.
One key approach in ML for TDM is Natural Language Processing (NLP), meaning using computers to understand the meaning, relationships, and semantics within human-language text. Generally for natural language processing, full text is needed. It is not a bag-of-words method.
Some common, specific methods under NLP are: Named entity extraction, Sentiment analysis and Stylometry.
Clustering#
Clustering is unsupervised machine learning.
Which texts are the most similar? Example: “Is this play closer to comedy or tragedy?”
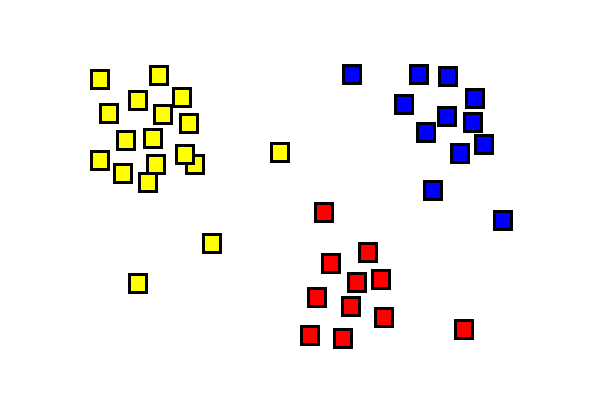
Image source: CreightonMA, Wikimedia, CC Attribution Share alike
{kind=link}
Classification#
Classification is supervised machine learning
Are there other texts similar to this? Example: “Are there other Jim Crow laws like these we have already identified? Supervised Machine Learning * The advent of *supervised machine learning techniques have rapidly changed text analysis in the digital humanities. These methods “train” computers to identify and classify similar items based on data that has been labeled or tagged by experts. For example, On the Books: Jim Crow and Algorithms of Resistance was able to use machine learning to identify 1939 North Carolina Jim Crow laws enacted between Reconstruction and the Civil Rights Movement.
Read more
William Mattingly Introduction to Machine Learning TAP Institute 2021
Grant Glass Introduction to Machine Learning TAP Institute 2021
Text Visualization#
Data visualization is the process of converting data sources into a visual representation. This representation is usually in graphical form. Broadly speaking, anything that displays data in some visual form can be called a data visualization, including both traditional graphs and charts, as well as more innovative data art.
Visualizations present particular ways of interpreting data. It is not a transparent, objective projection of what the data is. By selecting different types of visualization and adjusting parameters, the resulting visualization is a researcher’s specific way of interpreting and presenting data.
See examples of text visualizations
Read about SEC Visualizations
Read about using Natural Language Processing (NLP) to analyze the Wall Street Bets Reddit group
Read more#
The M.E. Test “… workshop for the US Latino Digital Humanities Center (USLDH) at the University of Houston on introductory text analysis concepts and Voyant. recording of talk & slides
Datasets as Primary Sources: An Archaeological Dig into Our Collective Brains, Part 1
“Data cleaning is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset. When combining multiple data sources, there are many opportunities for data to be duplicated or mislabeled.”
How do you clean data?
Step 1: Remove duplicate or irrelevant observations
Step 2: Fix structural errors
Step 3: Filter unwanted outliers
Step 4: Handle missing data
Step 5: Validate and QA (quality assurance)
Keywords in Digital Pedagogy in the Humanities: Text analysis
When getting started with computational methods, looking up terms (such as Text Mining) on Wikipedia is helpful.
Attribution#
Some content on this page adapted from:
Text Analysis: What Every Digital Humanist Should Know created by Nathan Kelber for JSTOR Labs under Creative Commons CC BY License. For notebooks from Text Analysis Pedagogy Institute, see the TAPI site.
Research Data Oxford and used under a Creative Commons Attribution 3.0 Unported License..
BOSTON COLLEGE LIBRARIES:Text & Data Mining and used under a Creative Commons Attribution 4.0 International License..
NYU Text Data Miningand used under a Creative Commons Attribution-NonCommercial 4.0 International License..
HTRC Digging Deeper, Reaching Further used under a Creative Commons Attribution-NonCommercial 4.0 International License.